
Warum ist die Betonung auf Kohärenz bei Datenflüssen heute wichtiger als die bloße Vervielfachung von Kanälen? Die Antwort liegt in konkreten Best-Practice-Empfehlungen großer Plattformanbieter und in den technischen Grenzen, die Unternehmen 2026 bei der Datenintegration und im Netzwerkmanagement spüren. Microsofts Richtlinien für Power BI-Datenflüsse und Fachartikel wie jene von StudySmarter heben die Operationalisierbarkeit und die Datenqualität als entscheidende Faktoren hervor.
Warum Kohärenz den Informationsfluss stabilisiert und Skalierung ermöglicht
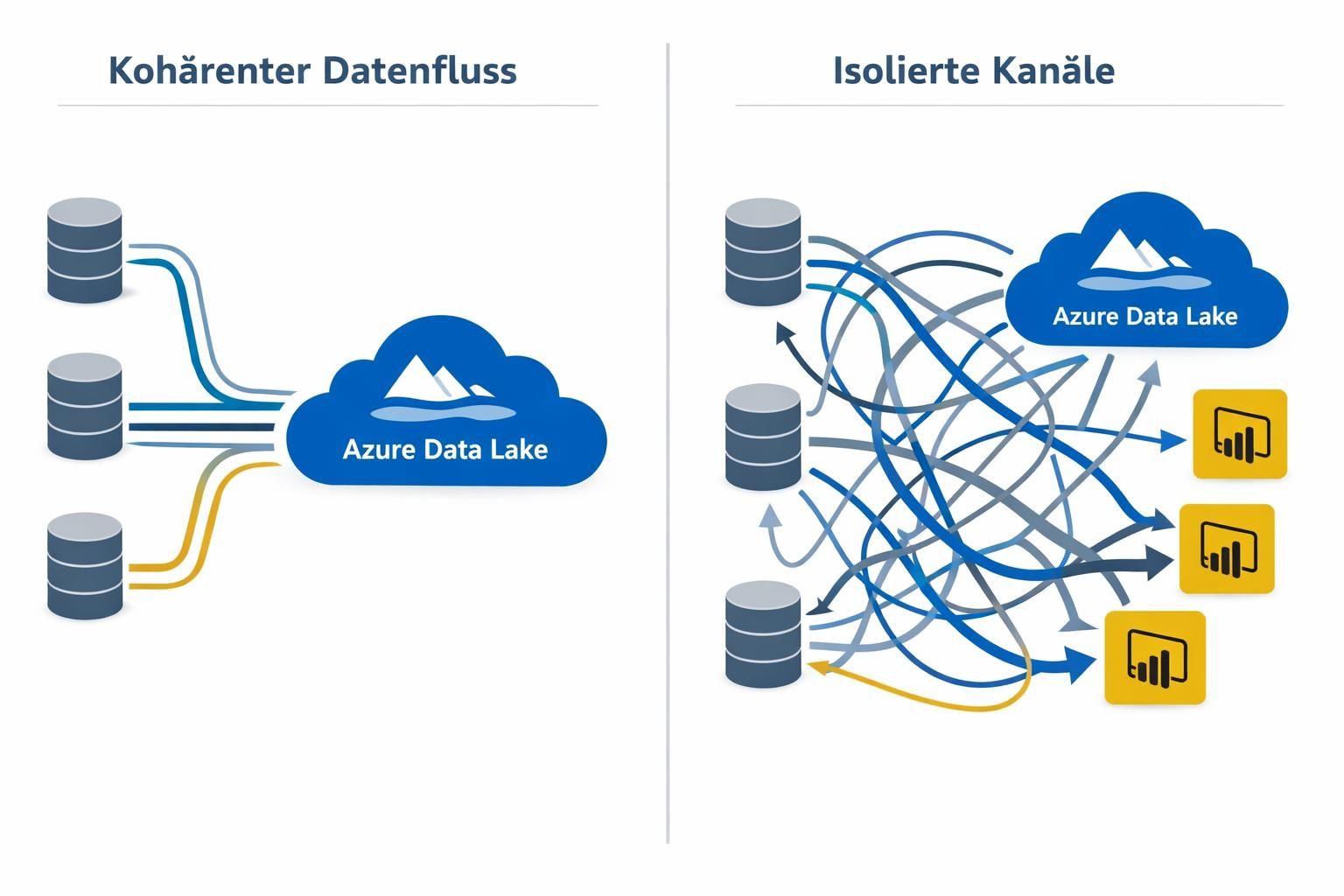
Unternehmen, die auf zahlreiche, isolierte Kanäle setzen, erzeugen oft einen fragmentierten Informationsfluss. Microsoft empfiehlt, komplexe Datenflüsse in mehrere, klar getrennte Datenflüsse aufzuteilen — etwa in Staging- und Transformationsflüsse — um Übersicht und Wiederverwendbarkeit zu erhöhen.
Kohärenz als Gegenmittel zur Kanal-Vervielfachung
Die Trennung nach Zweck erlaubt es, Aktualisierungspläne zu differenzieren und verhindert, dass regelmäßig aktualisierte Tabellen durch seltene Referenztabellen blockiert werden. Das reduziert Locking-Probleme in Arbeitsbereichen und verbessert die Kommunikationseffizienz zwischen Teams.
Ein klarer Systemzusammenhang macht zudem Fehlerquellen sichtbar und erhöht die Analysegenauigkeit. Am Ende steht eine belastbarere, leichter skalierbare Datenarchitektur mit besserer Datenqualität.
Technische Praktiken zur Sicherung von Kohärenz in Data Pipelines
Konkrete Maßnahmen, die Microsoft in der Dokumentation vorschlägt, sind sofort umsetzbar: Einsatz von benutzerdefinierten Funktionen in Power Query, Nutzung berechneter Tabellen zur Leistungssteigerung und das Speichern von Staging-Daten in Dataverse oder Azure Data Lake Storage.
Von Design zu Betrieb: Schritte und Beispiele
Beispielsweise empfiehlt es sich, lokale von Cloud-Quellen zu trennen und Datenflüsse nach Aktualisierungshäufigkeit aufzuteilen. Solche Konfigurationen minimieren interne Grenzwerte bei Aktualisierungen und erleichtern das Troubleshooting.
Die Nutzung einer erweiterten Compute-Engine und die Aufteilung komplexer Transformationen in mehrere Abfragen reduzieren Laufzeiten und verbessern den Systemzusammenhang. Dokumentation in Form von Abfrageeigenschaften erhöht die Nachvollziehbarkeit und verringert technische Schulungskosten.
Auswirkungen auf Unternehmen, Plattformen und den digitalen Markt
Für Plattformbetreiber und Dienstleister heißt das: Mehr Kanäle schaffen nicht automatisch Mehrwert. Studien und Praxisberichte zeigen, dass fehlende Kohärenz zu Dateninkonsistenzen führt und die betriebliche Agilität einschränkt. Die Folge sind erhöhte Kosten für Datenbereinigung und längere Time-to-Insight.
Marktbeispiele und Folgen für die Branche
Bildungsplattformen wie StudySmarter liefern begleitende Inhalte zur Erklärung von Datenflüssen; solche Ressourcen dokumentieren, dass Transparenz und Modellierung essenziell sind. Anbieter von Analyse- und Streaming-Technologien (z. B. Kafka, Spark) betonen 2026 vermehrt Integrationsszenarien statt reiner Kanalexpansion.
Für CIOs und Data Engineers bedeutet das konkret: Investitionen in Datenintegration, Observability und Netzwerkmanagement zahlen sich aus. Wer Kohärenz herstellt, verbessert die Kommunikationseffizienz zwischen Fachbereichen, reduziert das Risiko von Datenverlust und schafft eine Basis für Automatisierung und resilientere Prozesse.
Der nächste Schritt für Organisationen besteht darin, bestehende Multi-Channel-Architekturen kritisch zu prüfen und gezielt Kohärenzmechanismen—wie modularisierte Datenflüsse, zentrale Speicherung und wiederverwendbare Funktionen—einzuführen, um langfristig robuste, skalierbare Datenlandschaften zu erreichen.






